RF 小市值增强策略
随机森林(Random Forest)
集成学习方法(Ensemble Learning)是一种机器学习技术,旨在通过组合多个基本模型(弱学习器或基学习器)的预测来提高整体性能和泛化能力。集成学习的核心思想是,通过结合多个模型的意见和决策,可以减少单个模型的误差,并在各种不同情况下获得更稳健的结果。集成学习方法通常比单个模型更强大,适用于各种机器学习任务,包括分类、回归和聚类等。
随机森林属于集成学习的一种,通过集成学习的 Bagging 思想将多棵树集成的一种算法:它的基本单元就是决策树。随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。例如,如果你训练了5个树,其中有4个树的结果是 True,1个数的结果是 False,那么最终投票结果就是 True。
随机森林原理
随机森林的数学原理涉及到随机抽样、特征选择、决策树构建和集成方法。
随机抽样
首先介绍自助采样法(bootstrap),如果我们有个大小为 N 的样本,我们希望从中得到 m 个大小为 N 的样本用来训练。那么我们可以这样做:首先,在 N 个样本里随机抽出一个样本 x1,然后记下来,放回去,再抽出一个 x2,……,这样重复 N 次,即可得到 N 的新样本,这个新样本里可能有重复的。把上面的方法重复 m 次,就得到了 m 个这样的样本。实际上就是一个有放回的随机抽样问题。每一个样本在每一次抽的时候有同样的概率(1/N)被抽中。
随机森林的 Bagging 基于自助采样法这种方法,将训练集分成 m 个新的训练集,然后在每个新训练集上构建一个模型,各自不相干,最后预测时我们将这 m 个模型的结果进行整合,得到最终结果。这个过程引入了数据的随机性,使得每棵决策树的训练数据都略有不同。
特征选择及决策树的构建
在每次决策树节点的分裂过程中,随机森林引入了特征的随机性。
决策树是用树的结构来构建分类模型,在每棵树中仅考虑有限数量的特征来拆分节点。假设总共有 M 个特征,从这些特征中随机选择 m 个特征来构建决策树。每个节点代表着一个属性,根据这个属性的划分,进入这个节点的子节点,直至叶子节点,每个叶子节点都表征着一定的类别,从而达到分类的目的。
那么决策树在每个节点是如何选择特征的呢?下面介绍决策树选择特征的几个指标。
信息增益
表示得知特征 X 的信息而使得类 Y 的信息的不确定性减少的程度。一般而言,信息增益越大则意味着用属性 a 来进行划分所获得的"纯度提升"越大。
著名的 ID3 决策树学习算法就是以信息增益为准则来选择划分属性。但 ID3 算法只适用于分类任务中,且该算法生成的树容易产生过拟合(因为 ID3 只有树的生成没有剪枝)。
信息增益比
又称为增益率。根据"信息增益"选择属性并划分结点存在一个问题:对可取值数目较多的属性有所偏好,比如"性别"只能取"男"或"女",而"年龄"可以取任意整数,则信息增益会偏好选择"年龄"作为属性进行结点划分,这就使得信息增益和熵之间的初衷产生了矛盾,而"增益率"通过在信息增益的基础上引入 IV 解决这一问题。IV 称为属性 a 的"固有值",可以看到属性 a 的可能取值数目越多(即 V 越大),则 IV(a) 的值越大,导致"增益率"越小。
C4.5 决策树是对 ID3 算法的改进,C4.5 算法采用信息增益比进行特征选择。
基尼指数
基尼指数与"信息增益"类似。不同于用"信息熵"度量不存度,它利用基尼值。直观来说,Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(D) 越小,则数据集 D 的纯度越高。CART 决策树采用基尼指数进行特征选择。
集成方法
在随机森林中,多个决策树的结果被集成以进行分类或回归。对于分类问题,最终的分类结果是通过多数投票法来确定;对于回归问题,最终的回归结果是多个决策树的预测结果的平均值。
策略执行流程
数据基础
- 训练数据:2020-01-01 至 2023-11-30 全市场 A 股日线数据
- 特征工程:构建 14 个量价及衍生特征,含 3/5/10/20 日收益率、5/10/20 日波动率、成交额均值、价格波动幅度、成交额比率、波动率比率、动量强度
- 标签定义:个股未来 5 日收益率跑赢当日全市场中位数为 1,否则为 0
- 数据处理:剔除特征或标签含缺失值的样本
随机森林模型训练与预测
模型训练:
- 训练方式:初始化阶段一次性训练
- 核心参数:
n_estimators=250, max_depth=15, min_samples_split=80, random_state=42, n_jobs=-1 - 特征处理:训练集数据标准化后输入模型
预测逻辑:
- 特征提取:调仓日提取个股当日 14 个量价特征
- 标准化:沿用训练集拟合的标准化器处理特征
- 输出结果:个股未来 5 日跑赢全市场中位数的分类预测值(1/0)
股票池构建
- 非 ST、非停牌、非科创板、非北交所
- 上市天数 > 252 天
- 流通市值 > 5 亿
选股逻辑
- 优先筛选:预测值为 1 的个股
- 排序方式:流通市值升序
- 持仓数量:前 5 只
- 兜底规则:无预测值为 1 的个股时,直接选取流通市值最小的 5 只
交易执行
- 调仓周期:每 5 个交易日
- 仓位管理:目标标的等权配置
- 交易规则:卖出非目标持仓,按开盘价下单;买入成本 0.03%,卖出成本 0.13%(最低 5 元/笔)
- 业绩基准:沪深 300 指数(000300.SH)
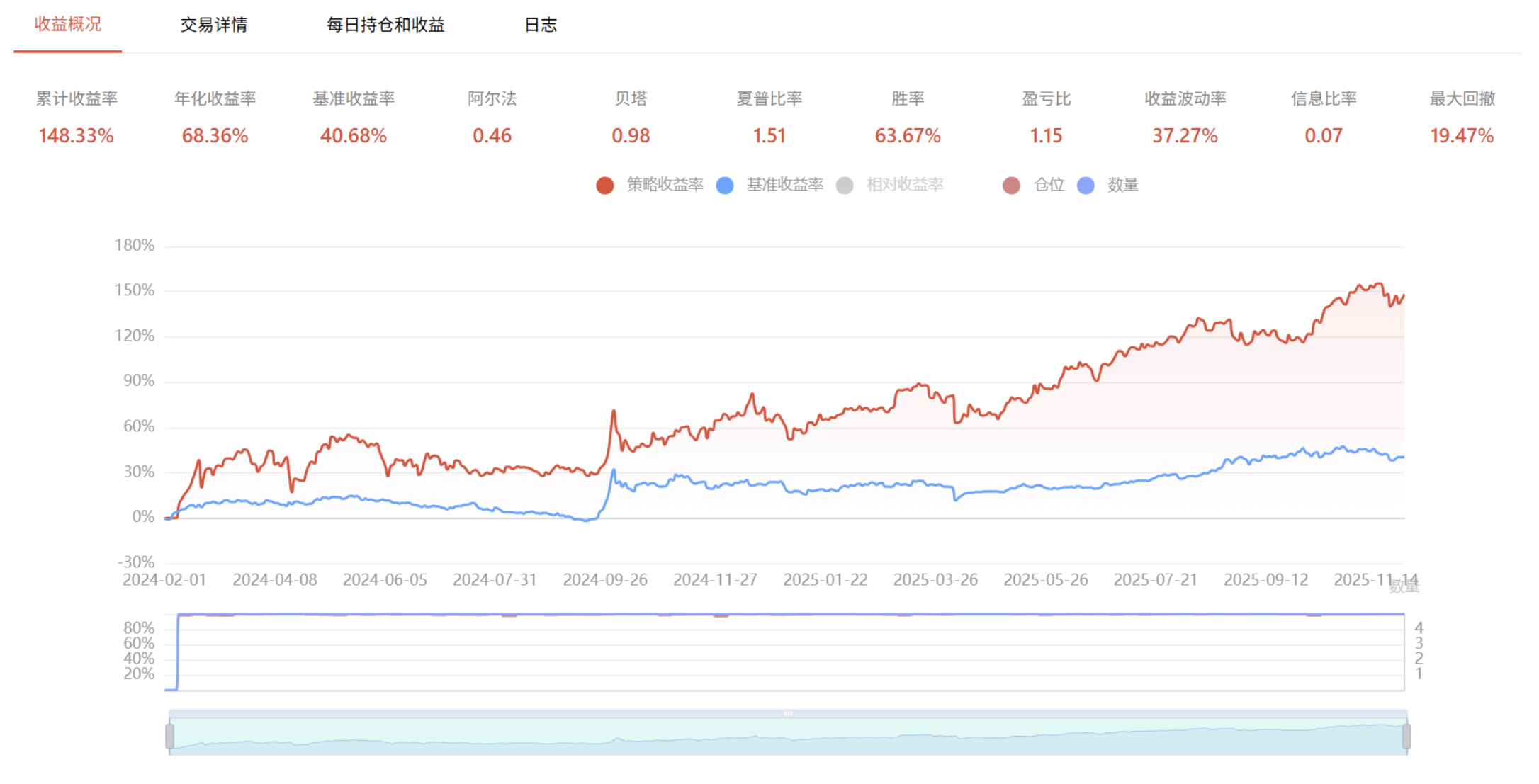
回测结果
模型学习时间为 2020 年 1 月 1 日 - 2023 年 11 月 30 日,回测时间为 2024 年 2 月 1 日 - 2025 年 12 月 2 日
改进方向
- 模型优化:特征大部分集中于量价及其衍生特征,可以加入更多特征进行训练如市场情绪因子(舆情情绪指数)、资金面特征(北向资金持仓占比)等
- 模型改进:采用滚动训练(如每 3 个月更新模型),适配市场风格变化,但是会增加算力消耗,一次性训练全量市场数据可能更为现实
- 策略优化:在随机森林训练的基础上可以叠加其他收益更好的策略进行尝试,如结合动量/低波动因子加权排序,或者新增基本面特征(如营收增速、净利润增速等)进行筛选
- 风控增强:加入止损规则(如单只个股亏损超 10% 强制卖出)或行业分散约束