收益率 300%?小心 PTrade 里的未来函数
我们在互联网上经常看到收益率非常离谱的策略回测,动不动年化 298.5%,夏普比率 6.30,让巴菲特、西蒙斯、索罗斯看到都沉默。
唯一的问题是:实盘账户……惨不忍睹!
小心,可能是未来函数在挖坑!
什么是未来函数
未来函数,在量化回测的语境中,指的是在回测过程中,一个策略无意中使用了在回测时点当时还无法获得的未来信息来进行交易决策。
就像至尊宝高举月光宝盒,一瞬间穿越回过去,带着未来的剧本改写结局。

简单来说,就是你让策略"偷看"了未来的答案,然后再做出"正确"的历史决策。这会导致回测结果极其优异,但在实盘交易中一败涂地,因为它基于不存在的、超前的信息。
回测中的未来函数,就相当于这个"偷看答案"的行为。回测系统是历史的"标准答案",而你的策略本应只根据"当时已知"的信息来交易。
未来函数的常见类型和例子
未来函数通常非常隐蔽,主要分为以下几类:
经典的数据偷窥
这是最直接的一种,即在交易信号生成时,使用了尚未发生的数据。
案例:日线数据在分钟线上回测
在 T 日早上 10:50,如果 T 日 5 日均线金叉 10 日均线,则立即买入。
❌ 错误做法:
h = get_history(20, "1d", field=["close", "volume"], security_list=g.security,
fq="dypre", include=True, is_dict=True)
close_data = h[g.security]["close"]
# 获取 5 日、10 日均线
ma5 = get_ma(close_data, 5)
ma10 = get_ma(close_data, 10)
问题:在 T 日中午 10:50,你根本无法知道 T 日的收盘价是多少,却用收盘价来计算均线,用它来生成交易信号。这相当于在交易日结束前就知道了结果。
✅ 正确做法:
在 T 日早上 10:50,你只能使用 T 日 10:50 的最新价来计算均线。
# 获取历史日 K 线数据
h = get_history(20, "1d", field=["close", "volume"], security_list=g.security,
fq="dypre", include=False, is_dict=True)
close_data = h[g.security]["close"]
# 获取最新价
current_price = get_history(1, "1m", field=["close", "volume"], security_list=g.security,
fq="dypre", include=False, is_dict=True)[g.security]["close"][0]
# 合成最新 K 线序列
close_data = np.concatenate((close_data, np.array(list([current_price]))), axis=0)
# 获取 5 日、10 日均线
ma5 = get_ma(close_data, 5)
ma10 = get_ma(close_data, 10)
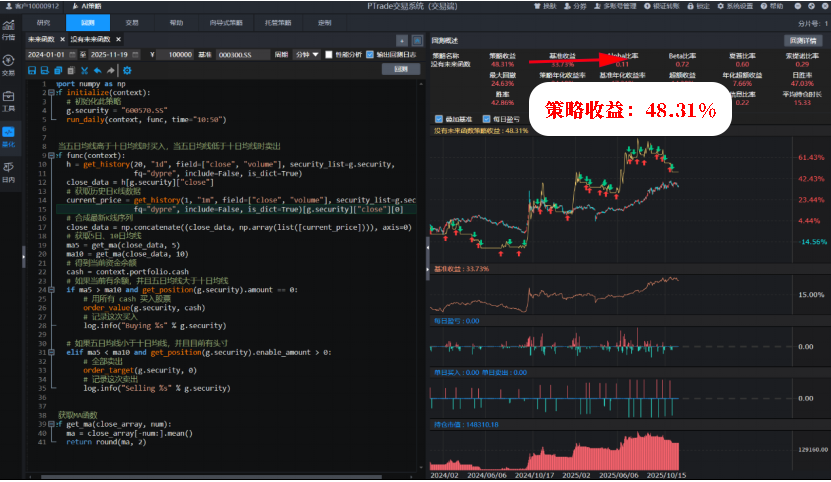
未来函数的回测结果:
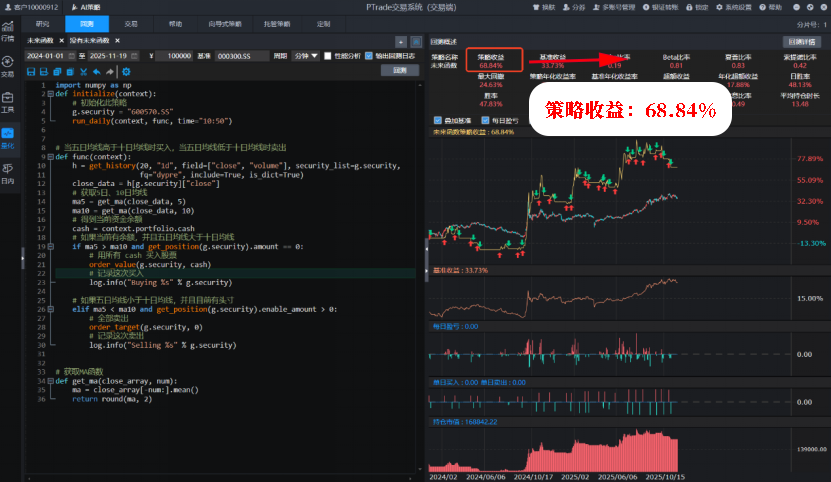
没有未来函数的回测结果:
时间轴偏差
这类错误发生在处理不同时间频率的数据,或者有发布延迟的数据时。
案例:使用财报数据
❌ 错误回测逻辑:
在上市公司发布季度财报的当天,如果每股收益(EPS)> 预期,则开盘买入。
问题:财报通常是在收盘后或盘前发布的。如果你使用 T 日开盘价买入,实际上你在开盘时已经知道了昨晚收盘后发布的财报信息。在真实的历史中,在 T 日开盘那一刻,这个财报信息是"已知"的,所以这个逻辑本身不算是未来函数。但如果财报是在 T 日上午 10:00 发布的,而你却用 T 日 9:30 的开盘价来回测,这就构成了未来函数,因为信号生成时信息还未发布。
✅ 正确做法:
确保在回测中,任何数据的可用时间都严格晚于其发布时间。例如,对于盘后发布的财报,最早的可交易价格是 T+1 日的开盘价。
备注:因为财务数据的使用极易造成未来函数,因此 PTrade 量化引擎做了修改,回测交易日当天仅能获取到上个交易日发布的财务数据,因此,用户在 PTrade 中可放心使用财务数据,无需担心未来函数风险。
前向平移 / 数据透视偏差
在数据处理和特征工程中非常常见,尤其是在机器学习领域。
案例:数据标准化
❌ 错误回测逻辑:
在整个回测区间上,先计算所有数据的均值和标准差,然后用这个全局的均值和标准差对每一天的数据进行标准化,再训练模型和预测。
问题:比如先在研究模块用 2022 年~2024 年三年的数据计算了全局值,在 2022 年 1 月 1 日开始进行回测,用之前计算的全局值来标准化当天的数据,从而进行数据训练,这显然是偷看了未来。
✅ 正确做法:
必须使用"滚动窗口"的方法。例如,在 2022 年 1 月 1 日,你只能使用 2019 年~2021 年的数据来计算均值和标准差,再用这个结果来标准化 2022 年 1 月 1 日的数据。
幸存者偏差
这可以看作一种更宏观的未来函数。
❌ 错误回测逻辑:
使用"当前"还在交易的股票构成的历史指数(如沪深 300)作为回测的股票池,从 10 年前开始回测。
问题:这个今天的股票池,剔除了那些在过去 10 年中因为业绩差、退市、被并购等原因而消失的股票。你的回测策略巧妙地避开了所有这些"地雷",因为你只投资了那些"幸存"下来的好公司。在真实历史中,你当时并不知道哪些公司会幸存。
✅ 正确做法:
使用"point-in-time"的股票池。例如,在回测 2015 年的交易时,你的股票池必须是 2015 年当时的指数成分股列表,其中包含了那些后来被剔除或退市的公司。
在回测周期中要每个交易日都用 get_index_stocks() 接口获取一遍成分股。
总之,规避未来函数是量化策略开发中不可逾越的底线。它不仅关乎回测结果的真实性,更直接影响实盘交易的成败。
回测不是为了做出一条漂亮的曲线,而是为了验证策略在真实市场中是否可行。
要避免未来函数,核心原则很简单:在哪个时间点做决策,就只能用那个时间点之前已经公开、可获取的数据。不管是计算指标、处理特征,还是选股票池,都需要严格遵循这个规则。